Interval spoľahlivosti
Čo je interval spoľahlivosti:
Je to odhad rozsahu použitého v štatistikách, ktorý obsahuje parameter populácie. Tento neznámy parameter populácie sa nachádza prostredníctvom vzorového modelu vypočítaného zo zozbieraných údajov .
Príklad: priemer vzorky odobratej x̅ sa môže alebo nemusí zhodovať so skutočným priemerom populácie μ. Za týmto účelom je možné uvažovať o rozsahu vzorkovacích prostriedkov, kde môže byť táto populácia priemerná. Čím dlhší je tento interval, tým väčšia je pravdepodobnosť výskytu tohto intervalu.
Interval spoľahlivosti je vyjadrený ako percento, vyjadrené úrovňou spoľahlivosti, pričom najviac indikovaných je 90%, 95% a 99%. Napríklad na obrázku nižšie máme 90% interval spoľahlivosti medzi jeho horným a dolným limitom (a a -a ).
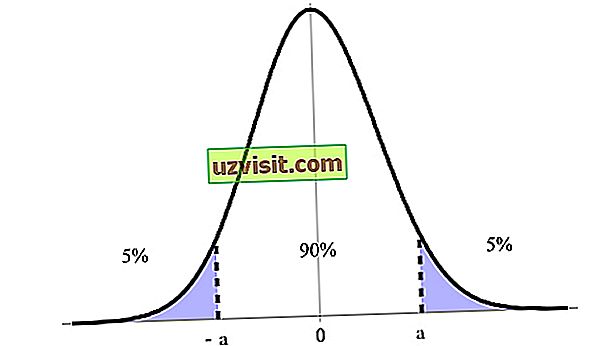
Interval spoľahlivosti je jednou z najdôležitejších koncepcií testovania hypotéz v štatistike, pretože sa používa ako miera neistoty. Termín zaviedol poľský matematik a štatistik Jerzy Neyman v roku 1937.
Aký je význam intervalu spoľahlivosti?
Interval spoľahlivosti je dôležitý na označenie miery neistoty (alebo nepresnosti) oproti výpočtu. Tento výpočet používa vzorku štúdie na odhad skutočnej veľkosti výsledku v zdrojovej populácii.
Výpočet intervalu spoľahlivosti je stratégia, ktorá berie do úvahy vzorkovanie chýb. Veľkosť výsledkov vašej štúdie a interval spoľahlivosti charakterizujú predpokladané hodnoty pre pôvodnú populáciu.
Čím užší je interval spoľahlivosti, tým väčšia je pravdepodobnosť, že percento študovanej populácie predstavuje reálny počet zdrojovej populácie, čo dáva väčšiu istotu, pokiaľ ide o výsledok študovaného objektu.
Ako interpretovať interval spoľahlivosti?
Správna interpretácia intervalu spoľahlivosti je pravdepodobne najnáročnejším aspektom tohto štatistického konceptu. Príkladom najbežnejšieho výkladu konceptu je:
Existuje 95% pravdepodobnosť, že v budúcnosti klesne skutočná hodnota parametra populácie (napr. Priemer) do rozsahu X (dolná hranica) a Y (horná hranica).
Interval spoľahlivosti sa teda interpretuje nasledovne: je 95% presvedčený, že interval medzi X (dolná hranica) a Y (horná hranica) obsahuje skutočnú hodnotu parametra populácie.
Bolo by úplne nesprávne tvrdiť, že: existuje 95% pravdepodobnosť, že interval medzi X (dolná hranica) a Y (horná hranica) obsahuje skutočnú hodnotu parametra populácie.
Vyššie uvedené vyhlásenie je najčastejšou chybnou predstavou o intervale spoľahlivosti. Po vypočítaní štatistického rozsahu môže obsahovať len parameter populácie.
Intervaly sa však môžu medzi jednotlivými vzorkami líšiť, zatiaľ čo skutočný parameter populácie je rovnaký bez ohľadu na vzorku.
Preto môže byť vyhlásenie o spoľahlivosti intervalu spoľahlivosti urobené len v prípade, keď sú intervaly spoľahlivosti prepočítané pre počet vzoriek.
Kroky výpočtu intervalu spoľahlivosti
Rozsah sa vypočíta pomocou nasledujúcich krokov:
- Zhromaždite údaje vzorky: n ;
- Vypočítajte priemer vzorky x̅;
- Určite, či je štandardná odchýlka populácie ( σ ) známa alebo neznáma;
- Ak je známa štandardná odchýlka populácie, môže sa použiť bod z pre zodpovedajúcu úroveň spoľahlivosti;
- Ak štandardná odchýlka populácie nie je známa, môžeme použiť štatistiku t pre zodpovedajúcu úroveň spoľahlivosti;
- Dolný a horný limit intervalu spoľahlivosti sa teda zistia pomocou nasledujúcich vzorcov:
a) Štandardná odchýlka známej populácie : \ t
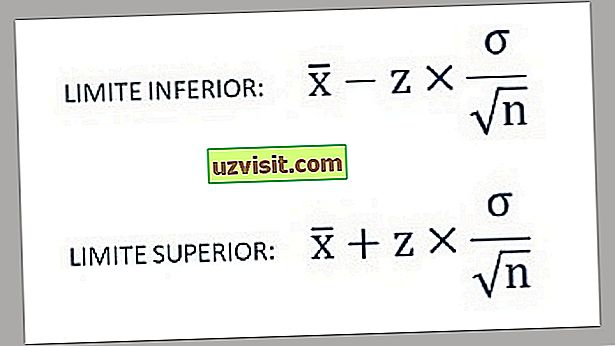
Vzorec pre výpočet štandardnej odchýlky známej populácie.
b) Štandardná odchýlka neznámej populácie :

Vzorec pre výpočet štandardnej odchýlky neznámej populácie.
Praktický príklad intervalu spoľahlivosti
Klinická štúdia hodnotila súvislosť medzi prítomnosťou astmy a rizikom vzniku obštrukčnej spánkovej apnoe u dospelých.
Niektorí dospelí boli náhodne prijatí zo zoznamu štátnych úradníkov, ktorí budú nasledovať štyri roky.
Účastníci s astmou mali v porovnaní s pacientmi bez rizika väčšie riziko vzniku apnoe v priebehu štyroch rokov.
Pri vykonávaní klinického výskumu, ako je tento príklad, sa podmnožina záujmovej skupiny obyčajne prijíma na zvýšenie efektívnosti štúdia (menej nákladov a menej času).
Táto podskupina jednotlivcov, študovaná populácia, sa skladá z tých, ktorí spĺňajú kritériá zaradenia a súhlasia s účasťou na štúdii, ako je znázornené na obrázku nižšie.

Potom sa štúdia dokončí a vypočíta sa veľkosť účinku (napríklad priemerný rozdiel alebo relatívne riziko ), aby sa odpovedala na výskumnú otázku.
Tento proces, nazývaný inferencia, zahŕňa použitie údajov zozbieraných zo študijnej populácie na odhad veľkosti skutočného vplyvu na populáciu, ktorá je predmetom záujmu, to znamená na populáciu pôvodu.
V uvedenom príklade výskumníci zobrali náhodnú vzorku štátnych zamestnancov (zdrojová populácia), ktorí boli oprávnení a súhlasili s účasťou na štúdii (populácia štúdie) a uviedli, že astma zvyšuje riziko vzniku apnoe v skúmanej populácii.
Aby sa zohľadnila chyba pri výbere vzorky v dôsledku náboru iba podskupiny záujmových skupín obyvateľstva, vypočítali aj interval spoľahlivosti 95% (okolo odhadu) 1, 06 - 1, 82, čo naznačuje pravdepodobnosť 95%. %, že skutočné relatívne riziko v zdrojovej populácii by bolo medzi 1, 06 a 1, 82 .
Interval spoľahlivosti pre priemer
Ak má človek informácie o štandardnej odchýlke populácie, je možné vypočítať interval spoľahlivosti pre priemer alebo priemer tejto populácie.
Ak je štatistická charakteristika, ktorá sa meria (napr. Príjem, IQ, cena, výška, množstvo alebo hmotnosť) číselná, vo väčšine prípadov sa odhaduje, že sa zistila priemerná hodnota pre obyvateľstvo.
Preto sa snažíme nájsť priemer populácie ( μ ) pomocou priemernej hodnoty vzorky ( x̅ ) s medzou chyby. Výsledok tohto výpočtu sa nazýva interval spoľahlivosti pre priemer populácie .
Ak je známa štandardná odchýlka populácie, vzorec pre interval spoľahlivosti (CI) pre priemer populácie je:

kde:
- x̅ je priemer vzorky;
- σ je štandardná odchýlka populácie;
- n je veľkosť vzorky;
- Ζ * predstavuje príslušnú hodnotu štandardného normálneho rozdelenia pre požadovanú úroveň spoľahlivosti.
Nižšie sú uvedené hodnoty pre rôzne úrovne spoľahlivosti ( Ζ * ):
| Úroveň dôvery | Hodnota Z * - |
|---|---|
| 80% | 01:28 |
| 90% | 1.645 (konvenčné) |
| 95% | 1.96 |
| 98% | 02:33 |
| 99% | 02:58 |
Vyššie uvedená tabuľka ukazuje hodnoty z * pre poskytnuté úrovne spoľahlivosti. Tieto hodnoty sa získavajú zo štandardného normálneho rozdelenia (Z-).
Plocha medzi každou hodnotou z * a záporom tejto hodnoty je (približná) percentuálna hodnota spoľahlivosti. Napríklad plocha medzi z * = 1, 28 a z = -1, 28 je približne 0, 80. Preto je možné túto tabuľku rozšíriť aj na iné percentá dôvery. Tabuľka zobrazuje iba najčastejšie používané percentá dôvery.
Pozri tiež význam hypotézy.